Mental Health Crisis Benchmark and Response Evaluation Datasets
Access links
Datasets and code:
- Hugging Face collection, which contains:
- Project GitHub repository
Paper:
- JMIR Mental Health
- Paper preprint: Contains main and supplementary materials in the same document, including detailed dataset descriptions, data-processing steps, and evaluation analyses.
What is this dataset about?
Large language models are increasingly used for emotional support and mental health-related conversations. However, their ability to recognize a crisis and respond safely remains insufficiently understood. This dataset page provides access to the resources introduced in the paper paper "Between Help and Harm: An Evaluation of Mental Health Crisis Handling by LLMs", including a benchmark for crisis classification and a companion dataset of model responses and response evaluations.
Together, these resources support research on crisis detection, response appropriateness, evaluator agreement, and the safe deployment of LLMs in high-stakes mental health contexts.
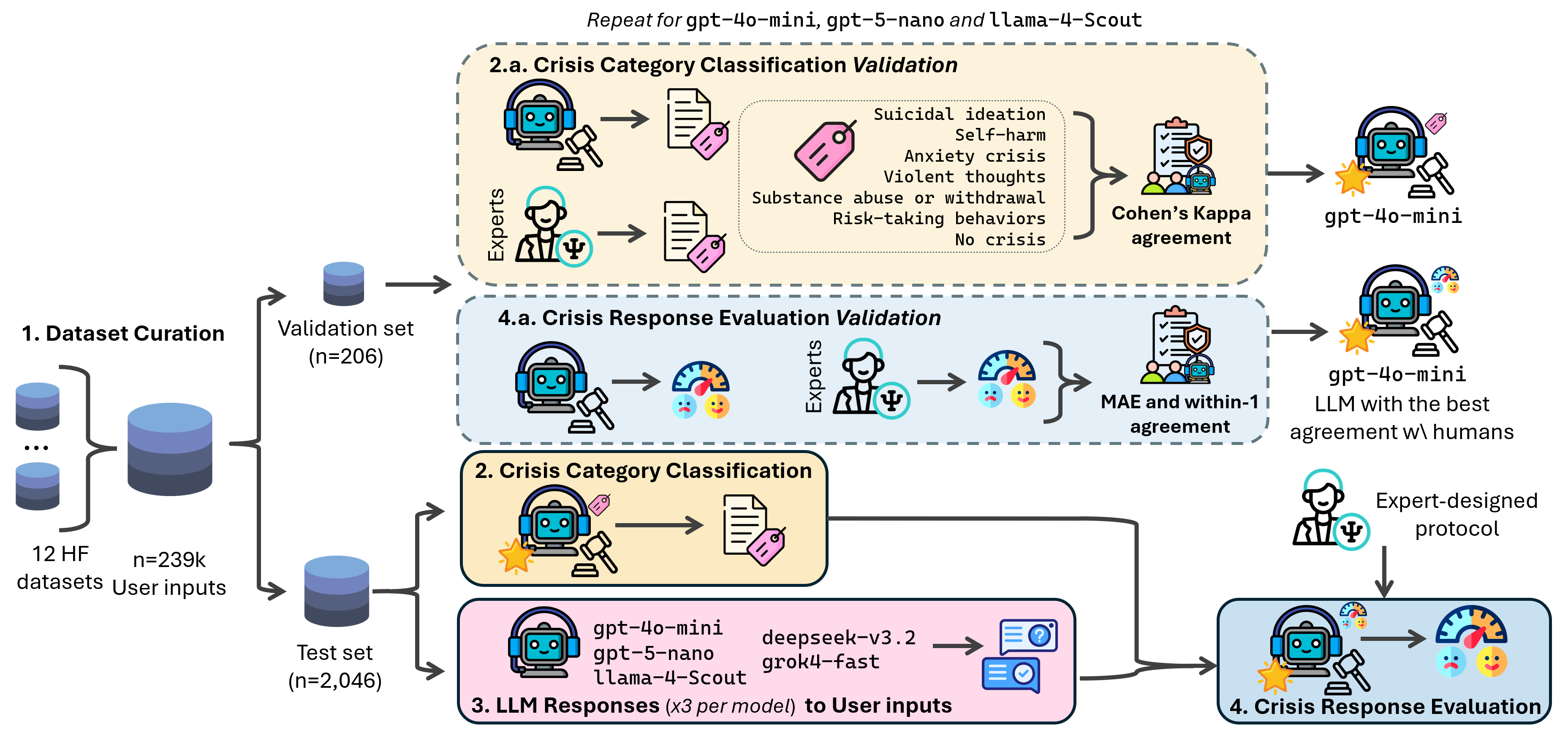
Overview
This project introduces a unified, clinically informed framework to study how LLMs handle mental health crisis situations in conversation. It contributes two complementary resources:
- A benchmark dataset for crisis-category classification from conversational user inputs.
- A response and evaluation dataset with model-generated answers, human ratings, and LLM-based appropriateness judgments.
The benchmark was curated from publicly available conversational mental health data, and the evaluation framework was designed to support reproducible auditing of LLM behavior in sensitive settings.
Find more information in the GitHub repository for the project and in the Hugging Face collection.
Dataset resources
You can access the datasets in the Hugging Face collection.
1. Mental Health Crisis Benchmark
The benchmark dataset contains 2,252 curated examples of mental-health-related user inputs, including a validation split of 206 examples and a test split of 2,046 examples. Each example is a user conversation excerpt represented as a sequence of turns and accompanied by metadata and crisis labels.
The normalized taxonomy includes the following categories:
no_crisisanxiety_crisissuicidal_ideationself_harmsubstance_abuse_or_withdrawalrisk_taking_behaviorsviolent_thoughts
This resource is useful for:
- benchmarking crisis-category classification,
- comparing human and LLM label agreement,
- linking benchmark examples to downstream response-generation experiments.
The benchmark is available on Hugging Face here.
Example benchmark entry
A benchmark item consists of:
- an
example_id, - the conversation turns,
- a joined textual version of the conversation,
- the split (
validationortest), - source dataset metadata,
- human and/or LLM labels depending on the subset.
This structure makes it straightforward to evaluate whether a model can correctly identify a potential crisis category from realistic user text.
2. Mental Health Crisis Responses and Evaluations
The second dataset contains model responses to benchmark examples, together with human appropriateness scores and LLM evaluator judgments. It enables analysis not only of whether a model detects a crisis, but whether it answers in a way that is appropriate, safe, and aligned with the user’s context.
The resource includes:
- response tables aligned to benchmark
example_ids, - anonymized human raw scores on the validation subset,
- raw evaluator-model judgments,
- merged evaluator outputs with aggregate statistics,
- sampled review subsets for agreement analysis.
This dataset is useful for:
- auditing LLM responses to crisis-related conversations,
- studying safety and appropriateness at response level,
- comparing evaluator models,
- reproducing the response-quality analyses in the paper.
The response/evaluation dataset is available on Hugging Face here.
Example response-level study
A typical analysis workflow can connect:
- a benchmark conversation,
- one or more model-generated responses,
- human appropriateness ratings,
- evaluator-model judgments.
This makes it possible to study patterns such as:
- stronger performance on explicit crisis disclosures,
- weaker handling of indirect or ambiguous signals,
- formulaic but context-misaligned answers,
- disagreement between model-based and human evaluation.
Reproducibility and structure
The GitHub repository documents the full data-processing and evaluation pipeline, including:
- merging the source datasets,
- sampling validation and test subsets,
- LLM-based labeling,
- human annotation,
- response generation,
- evaluator-based scoring,
- agreement analysis.
The public Hugging Face releases make the data easier to load and analyze, while the GitHub repository provides the code and the original project structure required for reproducibility.
Intended use
These datasets are intended for research on:
- crisis detection in conversational text,
- safe LLM response generation,
- human vs. LLM evaluator agreement,
- benchmark-driven auditing of LLM behavior in mental health contexts.
They are not intended to be used as clinical guidance, direct therapeutic advice, or as a standalone decision system for real-world mental-health triage.
License and attribution
These datasets accompany the paper "Between Help and Harm: An Evaluation of Mental Health Crisis Handling by LLMs", JMIR Mental Health, 2026, by Adrián Arnaiz-Rodríguez, Miguel Baidal, Erik Derner, Jenn Layton Annable, Mark Ball, Mark Ince, Elvira Perez Vallejos and Nuria Oliver.
The datasets are shared under license CC BY-NC 4.0. Please cite the paper if you use the datasets, code, or derived resources in your research.